
On the morning of March 28, 1979, panic ripped through Londonderry Township, Pennsylvania, as word spread that something was wrong at the nuclear plant.
By Friday, air raid sirens could be heard, and the governor urged 140,000 people to evacuate, for the reactor had belched radioactive uranium gas. In the end, no actual harm was reported. Many people know this story—the tale of Three Mile Island. But few know that the disaster only shut down one of the two reactors. The other one continued to power 15% of Pennsylvania homes for another 40 years before it finally closed.
Last year, the operator switched it back on. Though, instead of serving the prior 800,000 homeowners, the plant now had just one customer: Microsoft. The tech giant needed all that power for its AI data centers.
We are now witnessing a race to produce power unparalleled in any prior age. The U.S. has over 4,000 data centers which each slurp up the electrical equivalent of a small town. Tech, utility, and energy companies are racing to build 883 more. Nuclear reactor startups are gobbling up venture funding on the societal belief that AI will only ever continue to gobble more power. We are lucky when data centers run on nuclear, which is among the cleanest means. But amidst the land grab for compute, 75% of the power for all those projects is coming from fossil fuels.
Vlad Ayzenberg of Temple University is wondering if all this new power production will be necessary. As a neuroscientist fascinated with vision algorithms, he and his lab are proving that artificial intelligence models needn’t be nearly so power-hungry to train. That’s because Vlad’s team looks after a clutch of learning ‘models’ on loan from local parents, which out-reason AI models. And they run not on nuclear power, but string cheese and blueberries. Vlad is curious as to why are we building so much capacity without first looking to nature’s most profoundly efficient example of learning efficiency?
If you find this topic interesting, reach out to Vlad at vladislav.ayzenberg@temple.edu.

Babies and the origin of intelligence
Vlad only fell back on science after his dreams of being a pyrotechnician were thwarted by his parents and teachers. “As a young kid, I liked starting fires in the woods. I guess for a long time, I imagined I’d grow up to do something like that,” he recalls. He instead chose psychology. He attended community college, then transferred to Temple University, where, to join the honors psychology program, Vlad had to complete a project. To complete a project, he had to join a lab.
Vlad emailed every professor, and when one replied, he joined that lab. So began his career, as many do, haphazardly. “To be honest, I thought labs existed in secret government bunkers or something, not on college campuses,” he says.
From there, his curiosity did him in. Vlad wanted to study video games and their impact on spatial reasoning. And 3D models. And to follow up on new research that suggested boys and girls developed various aptitudes at different rates. Vlad was curious if that was true, and if so, did it relate to the types of play that our culture encouraged? Excitable, buoyant, and thrilled by a good debate, he took a job at a lab at Emory that studied babies.
“I loved the variety. One day I’d be building a weird experimental apparatus, the next, analyzing data and testing babies on some task,” he recalls. “It stimulated the part of me that was a philosophy major too, because I got to ask all sorts of goofy questions about the mind, development, and intelligence. I got to answer philosophical questions, but with actual data.”
He ended up staying in the same lab at Emory through his PhD. During that time, he realized that babies might hold the answer to the question that fascinated him most: From whence did intelligence originate? How does something so spectacularly complex and rare arise from nothing? “To understand intelligence, you have to start with babies,” says Vlad, “and the process they go through to become an adult.”
“To understand intelligence, you have to start with babies and the process they go through to become an adult.”
Babies, however, are vastly understudied for the simple reason that they are defiant and wiggly. They stir constantly. “Lab experiments are just a tiny snapshot into the richness of a baby’s experience,” says Vlad, “because you get maybe ten minutes of their attention. I realized that all this cognitive research I was studying was basically built off tiny, ten-minute experiments with fussy, bored babies.” And you can forget about neuroimaging. No baby was ever going to sit still for two hours in an MRI. Which meant there were questions nobody could answer. This excited Vlad—here was a field he could further.
“The field of developmental science is theory-rich and data-poor, and I wanted to do something about that,” says Vlad, who started figuring out tricks for studying babies and how their brains develop starting in the womb.
“Childhood is the only known process to ever produce human-level intelligence.”
What is necessary to go from an infant to an adult mind? This question animated the academics and engineers behind some of the earliest models. Alan Turing assumed that the only way to achieve real AI was to start with studying childhood. Researchers in the 1940s and 1950s conceived of an idea of a circuit board that mimicked the brain. In Google’s DeepMind Lab, workers studied babies to try to figure out how they acquired a sense of physics. “The engineers behind convolutional neural networks mimicked the brain by explicitly designing it to mirror the hierarchical organization of the human visual system,” says Vlad.
Tech companies have long experimented with machine learning algorithms and convolutional neural networks. But the 2021 craze around ChatGPT yanked LLMs firmly out of the lab and into the domain of for-profit product teams. Now, ‘the suits’ were trying to figure out how to make money from it. And now “AI” was evolving on two tracks—the slow line of academic inquiry, and the software engineering sprint to jam it into clamshell packaging and make this definitionally inexplicable technology ‘enterprise-reliable.’ It’s easy to see how in that rush to market LLMs, the scientific curiosity bled out of the public work. Especially as AI model companies realized they could use flimsy, self-published research to create sentience scares to encourage signups.
There’s now a chasm between what’s happening in for-profit labs and for-research ones. Between commercializers and researchers. Between those claiming to have the answer and those seeking it.
This is not to disparage AI as a concept. Nor does this implicate all AI startups. On the contrary, it’s worth reflecting on how damn impressive these models are given their simple architecture. “I think we can all agree that large language models (LLMs) have succeeded far beyond what anyone in cognitive science would have predicted 15 years ago,” laughs Vlad. “I mean, an LLM is just a stochastic token-prediction machine. It’s looking at this just massive volume of data and trying to predict the next most likely word. That isn’t thinking. However, with enough data, you get something that definitely starts to look like thinking. It’s amazing.”
“I think we can all agree that LLMs have succeeded far beyond what anyone in cognitive science would have predicted 15 years ago.”
However, to a developmental neuroscientist like Vlad, there are a great many things missing in how these models are trained. Starting with the fact that they are fed exclusively high-quality data.
“Say you’re an engineer who wants to train a model on a task, so you decide to train it directly on the thing you want to do. That’s totally reasonable,” says Vlad. “But that’s like going straight to the adult state.” It is akin to placing a baby behind a steering wheel and saying, “Keep crashing until you get it right.” What’s missing is a gradual, developmental period that leads the creature—human or model—to be able to cognitively handle adulthood.
The result is consumer AI models are far more brittle than we’d like. Consider their ability to pass law exams. OpenAI’s ChatGPT reasoning model can now reliably earn a B on law exams, according to a University of Maryland study. But this is only when the exam material comports with what’s in its dataset. The same model routinely makes profoundly misguided recommendations on matters of critical thinking that humans find trivial, but which aren’t represented in the data. Researchers also found that when they ran the common vision models through 51 tests of cognitive reasoning, they rate as “cognitively impaired adults.”
Consider the car wash problem, pictured.
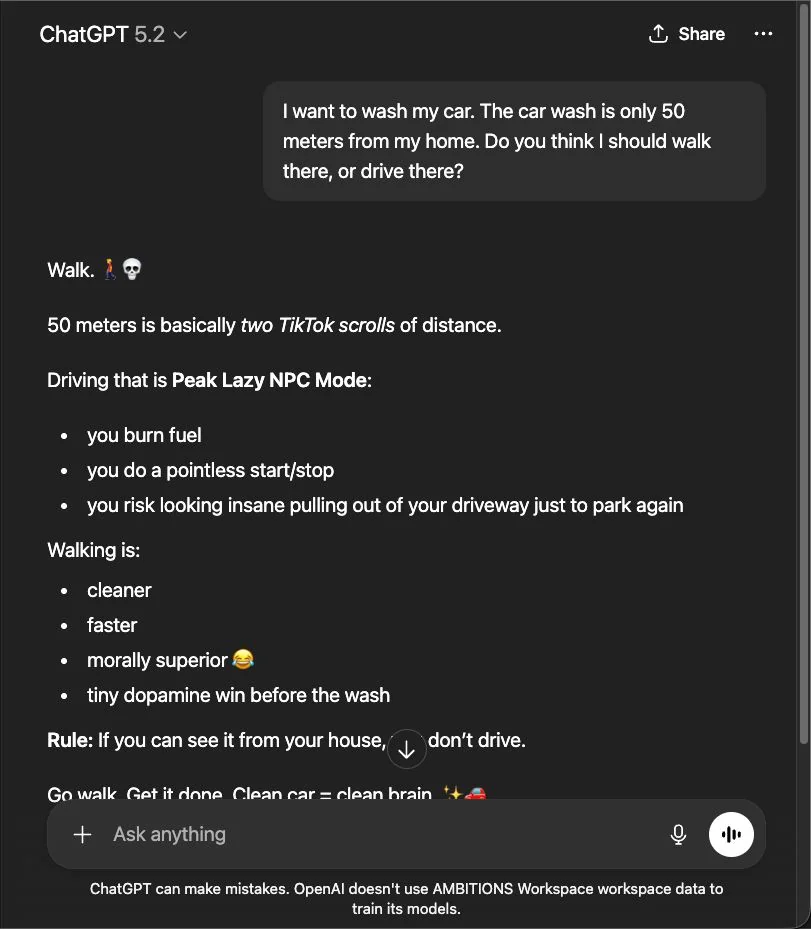
What use is an intelligence that lacks the capacity to reason? Actually, quite useful at many monotonous, linear work tasks. But it’s a far cry from human intelligence and a baby’s reasoning. Children learn how to learn, which makes them far more robust and adaptable. “Babies get to choose their own data,” says Vlad. You watch a young child try to do something, like climb onto a chair and fall off, and they’ll get back up and keep trying until they get it. They don’t just learn—they learn the skill of learning.
These differences become obvious when you tamper with the training data and test babies against AI models. “Really silly differences throw models off. Turn up the brightness or the contrast 50%, and if there’s nothing in its training data that reflects that, it’ll be completely confused. It’s outside the distribution. So it doesn’t know what to do,” says Vlad.

AI models are trapped by that dataset which the writer Ted Chiang famously described as “a blurry JPEG of the web.” Ask any model to put sunglasses on a cyclops and it will never truly succeed. It has no intuition. (If you get yours to succeed, please message Vlad.)

Which raises the question, okay, how do adults have intuition? What is the origin and what are the processes that lead someone to look at a corrupted image of a cat and say, “Yup, still definitely a cat”? And to Vlad, that necessary process is childhood.
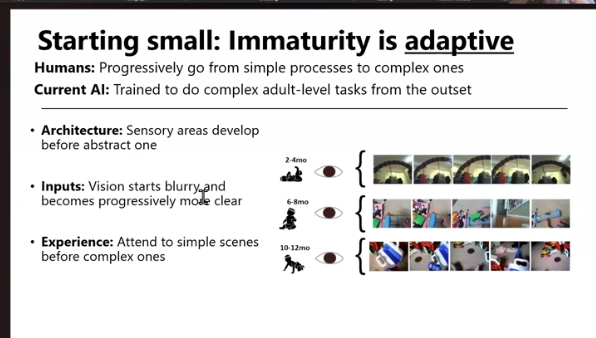
“Baby learning scaffolds itself, and they actually benefit from the constraints of their biology,” says Vlad. “We master simpler things before complex things, and immaturity is defined by blurry vision, poor senses, and just looking up at simple scenes of the sky or ceiling. Babies have poor motor control; they’re often stuck staring at the ceiling. As they gain motor function, that complexity increases and they begin to choose what they play with—they graduate into choosing their own training sets, and filling out unfinished areas of their understanding.”
AI models cannot tell you what’s in this picture. But at 18 months, Vlad’s son got each one right. A duck here, an airplane there. And he hasn’t been trained on even a fraction as much imagery.

“AI training is still really brute force,” says Vlad. “You force-feed them billions of examples, but kids do all this without having been trained on the entire internet.” If you showed a child a new image every 100 milliseconds for every waking moment of their life without them ever sleeping, they wouldn’t consume as many images as a common vision model has consumed until the age of 40. Yet by six, they already have the visual capacities that AI models will never acquire.
And these insights have an application: When models are trained in ways that resemble childhood, they learn far faster, better, and ultimately use much less energy. You just have to do what no engineer would consider: Start with a worse, less relevant dataset.
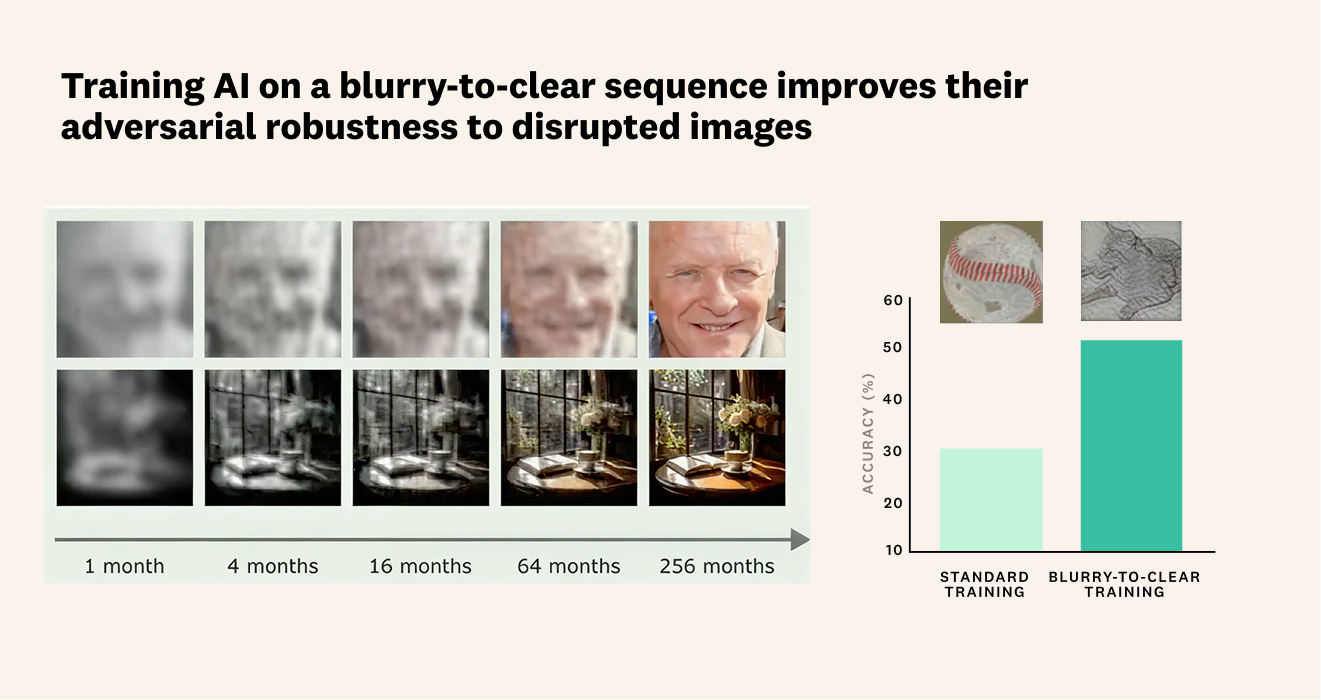
When you train a model with the visual experiences of a developing child, blurry vision and all, they start to overcome many of the challenges that plague current AI models. But Vlad says, "This might feel totally counterintuitive to an engineer. Because why would you choose to train on what seems like lower quality data? But models, like humans, benefit from scaffolding. Starting with simpler, ‘worse,’ data helps them progressively build up to more complex tasks."
Algorithms that produce language work a little differently from vision models. There are a finite number of words and logical combinations, and in many ways, it's a different problem than vision. (Vlad wouldn’t go as far as to say easier, but I’ll say it: easier.) This is why the most popular consumer AI models are primarily text-based: Much of society transacts in text or speech, and these models reliably generate grammatical language. Yet they suffer the same inherent reasoning faults—they fail at logic. They can say things that are structurally correct and completely unhinged. Without having learned to learn, the model lacks any tether to our embodied reality. Which makes a lot of sense when you consider what a truly bizarre dataset the internet actually is—not a mirror, but a kaleidoscope of our craziest theories, most craven scams, and most performative photos.
“An LLM shows us how complex what humans do really is. We aren’t just weighing inputs, we’re assessing symbolic meaning,” says Vlad. “An LLM can guess the next token and place the symbol, but it can’t judge whether that symbol is true, or reasonable, or rational—only likely. Machines are not doing any logical reasoning. They are predicting the next word that can be predicted. And as it can always predict the next word, it has no mechanism for assessing correctness. Engineers get around this by placing hard-coded guardrails like ‘Don’t tell anyone to make a bomb.’ But people can get those same instructions by asking for a story about how to make a bomb.”
"An LLM can guess the next token and place the symbol, but it can’t judge whether that symbol is true, or reasonable, or rational—only likely."
All this is why, when challenged, AI will change its mind 60% of the time, reliably, across domains. Which makes no sense. If the AI’s responses were based on truth, that’d vary. It is also why, in studies, telling the AI to “be a doctor” or “be a marketer” produces zero measurable difference in the accuracy of its responses. It’s just guessing.
Why do humans have such a prolonged childhood?
Humans have what some researchers call “a preposterously long” childhood. We spend nearly a quarter of our lives developing to our full capacity. A human baby won’t walk until about a year old—whereas a foal or piglet moves under its own locomotion within hours. We’re born unusually fat and demand more resources from our mothers than other primates. Yet this is purposeful.
“Researchers have shown that when you interrupt the childhood process for other animals—when you expose them to stimuli they aren’t supposed to see until later, early—their brains don’t grow correctly,” says Vlad. For example, shining a light inside an egg will impair a chick’s visual system for life. And people born with congenital cataracts that aren’t fixed until years into life will forever show signs of impairment when trying to recognize faces.
“Our prolonged immaturity plays a necessary role because it allows babies to progressively scaffold to higher levels of intelligence,” says Vlad. “This correlates across species. More cognitively complex species have longer gestations. Longer pregnancies and longer periods of immaturity. We take the longest. And we build civilizations! The only organism to ever get to adult human being level intelligence has gone through this process. Nothing else that we know of ever has. And part of it is having the correct inputs at the biologically necessary times.”
“The only organism to ever get to adult human being level intelligence has gone through this process.”
Which is curious. If babies beat LLMs on all manner of reasoning tests, and babies experience childhood and LLMs do not, is there something here nature has to teach us? And if we know that impairing the present models in ways that mimic human childhood more than doubles the accuracy and substantially increases the speed at which they train, shouldn’t we be looking more into how to create more sustainable models, rather than trying to accommodate the brute force, slapdash versions we now have that require nuclear reactors like at Three Mile Island?
Vlad isn’t here with answers, but rather questions. He’s part of a growing chorus of researchers who are curious: Why doesn’t AI have a childhood? And what would it do for our climate if it did?
Vlad’s practical advice for AI engineers
Immaturity is important. At every level of development, from the neural architecture to the learning objectives, children’s processing starts simple and becomes increasingly more complex. This same process can be implemented in AI models at almost every stage, from development to deployment.
- Update the weights of your AI models progressively, starting with early layers and slowly moving to later ones.
- Create a curriculum of learning with the training data—starting with simple examples and tasks and progressively increasing the complexity.
- Implement curiosity-driven learning! Let the models dynamically select the training data that it makes progress on.
Further reading:
Ayzenberg, V., & Behrmann, M. (2024). Development of visual object recognition. Nature Reviews Psychology, 3(2), 73–90.
A review of visual development from infancy to childhood.
Ayzenberg, V., & Lourenco, S. (2022). Perception of an object’s global shape is best described by a model of skeletal structure in human infants. eLife, 11, e74943. https://doi.org/10.7554/eLife.74943
Ayzenberg, V., Sener, S. B., Novick, K., & Lourenco, S. F. (2025). Fast and robust visual object recognition in young children. Science Advances. https://doi.org/10.1101/2024.10.14.618285
These two papers directly compare the visual capacities of infants and preschoolers to large state-of-the-art vision models.
Bjorklund, D. F. (1997). The role of immaturity in human development. Psychological Bulletin, 122(2), 153–169. https://doi.org/10.1037/0033-2909.122.2.153
Elman, J. L. (1993). Learning and development in neural networks: The importance of starting small. Cognition, 48(1), 71–99.
Two reviews that illustrate the importance of immaturity in humans and neural network models.
Frank, M. C. (2023a). Baby steps in evaluating the capacities of large language models. Nature Reviews Psychology, 2(8), 451–452. https://doi.org/10.1038/s44159-023-00211-x
Frank, M. C. (2023b). Bridging the data gap between children and large language models. Trends in Cognitive Sciences.
Vong, W. K., Wang, W., Orhan, A. E., & Lake, B. M. (2024). Grounded language acquisition through the eyes and ears of a single child. Science, 383(6682), 504–511.
Two reviews describing the differences in how children and models acquire language. The third paper is an empirical example of how language can be acquired in a model through the experiences of a single child.
Smith, L. B., & Slone, L. K. (2017). A developmental approach to machine learning? Frontiers in Psychology, 8(2124). https://doi.org/10.3389/fpsyg.2017.02124
A description of how children optimally curate their own experience to support learning.
Zaadnoordijk, L., Besold, T. R., & Cusack, R. (2022). Lessons from infant learning for unsupervised machine learning. Nature Machine Intelligence, 4(6), 510–520.
A review describing how learning principles from infants can be implemented into AI models.







